It's Not Bing or Google. The Search Engine Powering ChatGPT Is Bright Data. And Here's the Proof
The Assumption Everyone Makes
When ChatGPT started browsing the web, the reasonable assumption was that it was powered by Bing — Microsoft is an OpenAI investor, and Bing had an early integration & partnership announcement. Some developers assumed Google. Others assumed it was a homegrown crawler like GPTBot.
All of those guesses land on the wrong layer of the stack.
The infrastructure that routes ChatGPT's real-time search queries is Bright Data — a web data platform formerly known as Luminati Networks. And there's a second, smaller layer called Labrador, an internal OpenAI pipeline used specifically for licensed news and academic content.
But here's the important nuance we need to establish upfront: saying "Bright Data powers ChatGPT search" is not the same as saying "Bing and Google have nothing to do with it." Bright Data is best understood as a middleware layer — and what sits underneath that layer is a deliberate, commercially-motivated black box. This distinction matters enormously for how you interpret the findings, and for what it means for your visibility strategy.
See It Yourself — Without Touching DevTools
Before we get into the technical deep-dive, there's a faster way to start exploring this for your own conversations.
Synscribe's ChatGPT Search Query Extractor is a free Chrome extension that surfaces the hidden search queries ChatGPT fires — the query fan-out, the reasoning label for each search round, the results count, and whether the queries were fuzzified — directly overlaid on your ChatGPT conversations. No DevTools, no API calls, no code required.
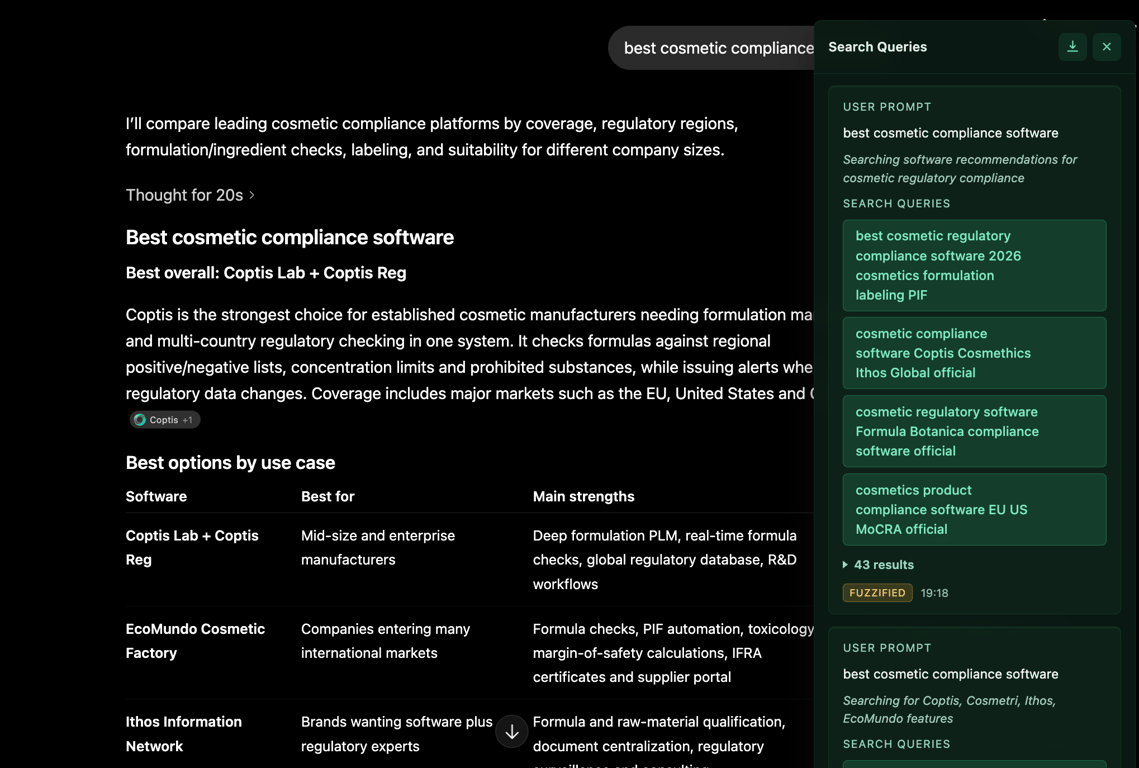 As you can see in the screenshot above, the panel surfaces exactly the data this article reverse-engineers manually: the user prompt, the
As you can see in the screenshot above, the panel surfaces exactly the data this article reverse-engineers manually: the user prompt, the reasoning_title (shown in italics as the search intent label), the individual system1_search_query strings, the result count, and a FUZZIFIED badge when Sonic couldn't execute the queries exactly as written.
The rest of this article goes deeper — into the raw API schema, which provider is returning those results, what each field means, and what it implies for optimization. But if you want to verify the findings hands-on as you read, install the extension first.
How We Found It: The Method
ChatGPT's backend API persists every search query, every tool call, and every result returned to the model — and it's queryable by any authenticated user. The endpoint is:
GET https://chatgpt.com/backend-api/conversation/{CONVERSATION_ID}
Authorization: Bearer {your_access_token}Your access token lives in a bootstrap script injected into every ChatGPT page:
const token = JSON.parse(
document.getElementById('client-bootstrap').textContent
).session.accessToken;The response contains a mapping object — a flat dictionary of every message in the conversation tree. When ChatGPT performs a web search, it generates a sequence of four message types:
An
assistant/codemessage — the JSON query payload sent to its search toolA
tool/web.runmessage — an echo of the queries received, with parsed query stringsAnother
tool/web.runmessage — the actual search resultsA fourth
tool/web.runmessage — a system notice if queries were fuzzified or approximated
We ran this extraction across three different conversations: cosmetic regulatory compliance software, food safety compliance software, and crypto/USDC payment options.
What the Data Shows
The Smoking Gun: result_source
Inside message.metadata.search_result_groups, every returned result carries a result_source field. Across all three conversations — 78, 184, and 123 results respectively — the breakdown was:
| Count | What it labels |
|---|---|---|
| 484 | Bright Data results |
| 5 | OpenAI news/academic pipeline |
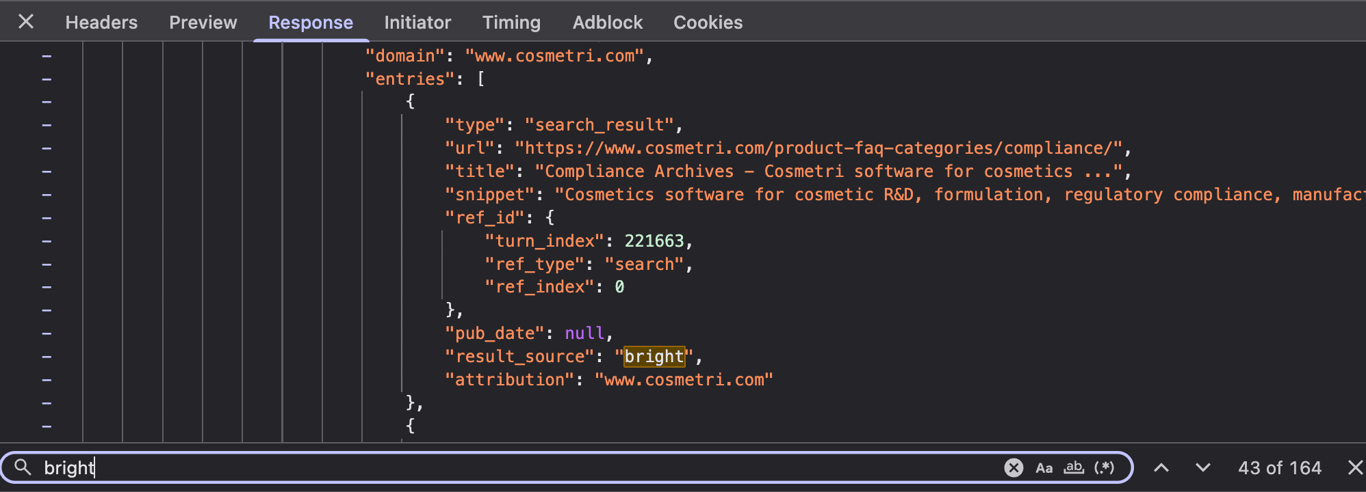 Every single general web result came back tagged
Every single general web result came back tagged result_source: "bright". There is no field value of "bing", "google", "brave", or any other named SERP provider anywhere in the raw data.
The Internal Codename: Sonic
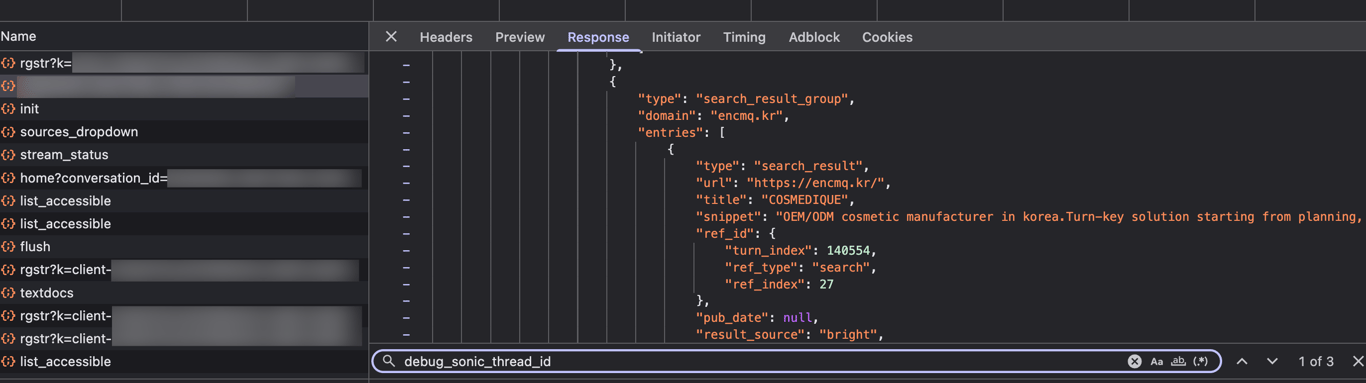
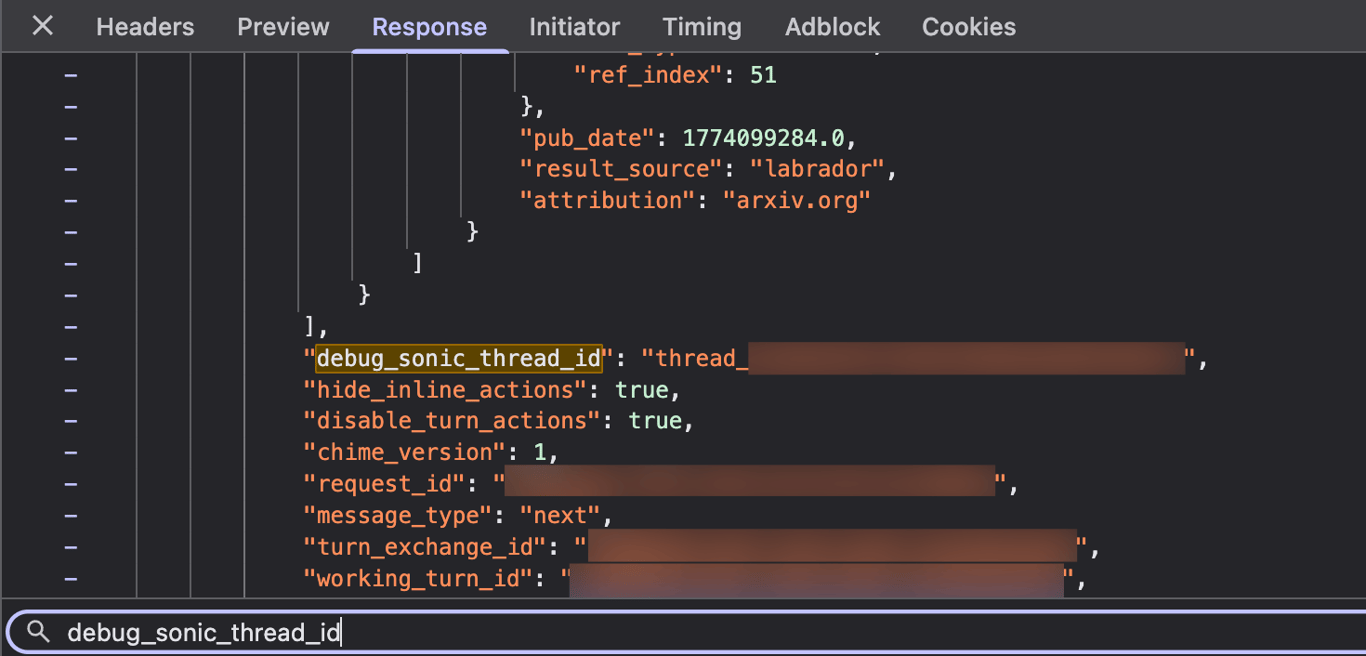 Every result-bearing tool message carries a field called
Every result-bearing tool message carries a field called debug_sonic_thread_id with a value like thread_6a32a418bef0d229d9248a99670e812d. This is OpenAI's internal codename for the search orchestration system. Sonic is the orchestrator. Bright Data is the retrieval layer it calls.
The Secondary Pipeline: Labrador
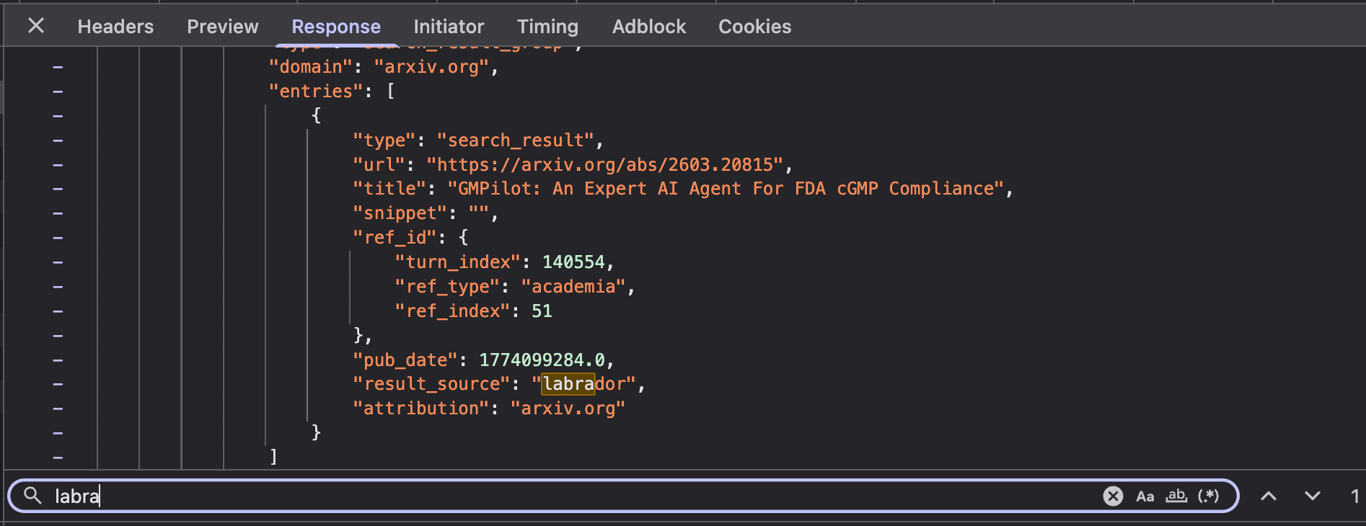 The five results tagged
The five results tagged "labrador" appeared on domains like reuters.com and marketwatch.com, and on arxiv.org. They always carry a distinct ref_type — either "news" or "academia" versus the standard "search" used for Bright Data results. More notably, their snippet fields contain full multi-paragraph article text, not the brief meta descriptions returned by Bright Data. This suggests Labrador is a licensed content pipeline with direct data agreements with premium publishers.
The Critical Caveat: Bright Data Is a Middleware Layer
Here is what the data does not tell us: what Bright Data queries underneath.
Bright Data's public SERP API product explicitly supports seven upstream search engines: Google, Bing, DuckDuckGo, Yandex, Baidu, Yahoo, and Naver — covering all 195 countries. Their product description is explicit: they provide "real user's results" by routing queries through their network and returning structured data. They are not, by default, a standalone search index. They are, at their core, a layer of abstraction over existing search infrastructure, combined with their own massive web archive (429 billion cached pages as of 2025) and proxy network.
So when ChatGPT fires the query "best cosmetic regulatory compliance software 2026" at Bright Data's endpoint, what happens next is unknown. Bright Data may query Google. It may query Bing. It may draw from its own cached index. It may blend results from multiple sources. It may route differently based on the query type, the geo-target, or the content category. That decision logic is entirely inside Bright Data's black box, and they have no public obligation to disclose it.
We attempted to verify this empirically: searching the exact query strings that appeared in ChatGPT's system1_search_query payloads directly in Google and Bing produced results that did not cleanly match what ChatGPT received.
The order was different, some results appeared in ChatGPT that didn't rank on the first page of either engine, and some top-ranking pages in Google were absent from ChatGPT's results. This is consistent with Bright Data applying its own ranking, blending, or caching layer on top of whatever raw engine results it retrieves — not a simple pass-through.
The accurate claim is this: Bright Data is the named, confirmed retrieval layer between OpenAI's Sonic orchestrator and the results ChatGPT generates its answers from. Whether Google or Bing powers Bright Data's backend — or some blend, or a proprietary index — is unknown, and deliberately so.
The Residential Proxy Angle: Bright Data's Unique Structural Advantage
One of the most strategically interesting aspects of Bright Data's architecture is how it retrieves web data. Unlike data center proxies (which search engines have long learned to detect and filter), Bright Data operates a network of 400 million+ residential IP addresses from real peer devices across 195 countries.
This has a direct consequence for ChatGPT search results that's rarely discussed: the results ChatGPT receives may be geo-personalized to your approximate location.
When a user in Singapore asks ChatGPT about crypto debit cards, Bright Data is likely routing that query through a residential IP in or near Singapore — fetching the version of Google or Bing results that a real Singaporean user would see. When a user in Germany asks about EU cosmetic regulatory compliance, the result set probably reflects what a German user's search would surface, including localized domains, language-adjusted rankings, and region-specific featured results.
This is not a minor footnote. Search results vary dramatically by geography. A product that ranks #1 in the US on Bing may not appear in the top 20 for the same query in Southeast Asia. By using residential proxies, Bright Data delivers localized search results that neither a standard API query to Bing nor a data center proxy fetch could replicate. It's one of their core selling points — their SERP API product page specifically highlights "Geo-location targeting" as a headline feature, with city-level granularity available.
The implication for appearing in ChatGPT answers: your visibility may vary by the user's location even for identical queries, in ways that wouldn't show up in standard rank-tracking tools pointed at a single geography.
Who Is Bright Data?
Bright Data (formerly Luminati Networks) was founded in 2014 in Israel. Their model is straightforward: they aggregate web data at scale, currently caching 429 billion web pages, and sell access to that data to enterprises.
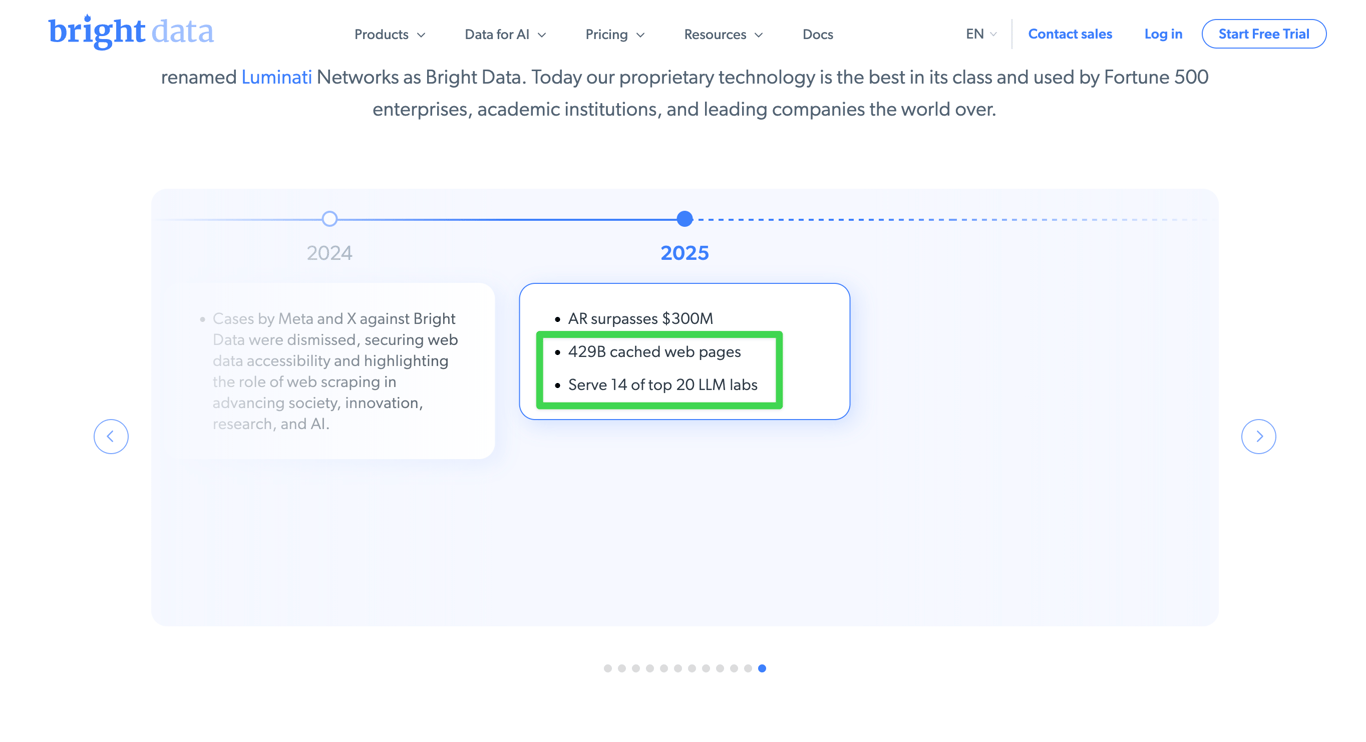 Their client list is notable. According to their own About page, they serve 14 of the top 20 LLM labs in the world with web data. Their publicly listed use cases include "AI Grounding" — described as: "Ground your LLMs in live information, reduce hallucinations, and continuously hydrate RAG pipelines and vector databases with fresh, structured content from across the open web." They also list "Apps Agents": "Enable your AI to search, extract, and interact with the web for real-time data."
Their client list is notable. According to their own About page, they serve 14 of the top 20 LLM labs in the world with web data. Their publicly listed use cases include "AI Grounding" — described as: "Ground your LLMs in live information, reduce hallucinations, and continuously hydrate RAG pipelines and vector databases with fresh, structured content from across the open web." They also list "Apps Agents": "Enable your AI to search, extract, and interact with the web for real-time data."
In 2024, cases brought against Bright Data by Meta and X were dismissed in court, establishing a legal precedent that ethical web scraping for legitimate business use is lawful. This ruling is significant context: OpenAI is partnering with a company that has legally defended the right to scrape the public web at scale.
How You Can Verify This Yourself
Step 1: Open a ChatGPT conversation that used web search (any conversation where ChatGPT cited sources).
Step 2: Get your access token from the browser console on chatgpt.com:
JSON.parse(document.getElementById('client-bootstrap').textContent).session.accessTokenStep 3: Extract the conversation ID from the URL: chatgpt.com/c/{THIS_PART}.
Step 4: Fetch the conversation data:
const convId = 'YOUR_CONVERSATION_ID';
const token = JSON.parse(document.getElementById('client-bootstrap').textContent).session.accessToken;
fetch(`https://chatgpt.com/backend-api/conversation/${convId}`, {
headers: { 'Authorization': `Bearer ${token}` }
}).then(r => r.json()).then(d => { window._conv = d; });Step 5: Extract all result sources:
const mapping = window._conv.mapping;
const sources = {};
Object.values(mapping).forEach(node => {
const m = node.message;
if (!m?.metadata?.search_result_groups) return;
m.metadata.search_result_groups.forEach(g => {
g.entries?.forEach(e => {
sources[e.result_source] = (sources[e.result_source] || 0) + 1;
});
});
});
console.log(sources); // { bright: N, labrador: M }Step 6: Cross-reference — take one of the actual query strings from the system1_search_query payload and search it manually in Google and Bing. Note whether the results match what ChatGPT received. In our testing, they don't match cleanly — which is the empirical evidence of the middleware black box in action.
The Full Data Schema
Each result entry returned through Bright Data contains:
Field | Notes |
|---|---|
| Full page URL |
| Page title |
| Meta description or text excerpt (~150 chars for |
| Unix timestamp (null for many pages) |
|
|
|
|
| Grouped by root domain |
| Display credit |
ChatGPT does not receive full crawled page content through this pipeline. The parts[0] content of the result tool messages is an empty string. Bright Data returns structured metadata — URL, title, snippet, date — not full documents. The exception is Labrador's news results, which appear to include full article text from licensed publishers.
What This Means for Appearing in ChatGPT Answers
Understanding the middleware architecture changes the optimization strategy considerably.
You Are Not Just Optimizing for Bing or Google
The mismatch we observed between manual Google/Bing searches and ChatGPT's results — same queries, different result sets — tells you that traditional SERP rank tracking is insufficient signal for ChatGPT visibility. Ranking #1 on Google does not guarantee you appear in ChatGPT results for the same query, because Bright Data may be routing through a different engine, a different geo, a cached version, or a blended result.
The correct frame is: you need to be indexable and snippet-worthy in Bright Data's retrieval layer, which in turn means being well-indexed across the major search engines and across Bright Data's own 429-billion-page web archive.
The Snippet Is Your Primary Interface With ChatGPT
Because ChatGPT receives snippets rather than full page text (for standard web results), your <meta description> tag is arguably your most important interface with the model. It's what ChatGPT reads when determining whether your page is relevant to a query. Write it as a direct, dense answer to the most likely query that would surface your page. Lead with the category, the problem solved, and the differentiator.
Recency Matters — But Differently Than You Think
The pub_date field in Bright Data's result entries is populated from page metadata and appears to influence result selection. Pages without publication dates, or with very old dates, appear less frequently in our test data. Importantly, this date comes from Bright Data's parsing of your page — not from a Google freshness signal. Keep cornerstone pages updated and ensure proper <time> and schema date markup.
Geo-Visibility Is Not Uniform
Because Bright Data routes queries through residential proxies matched to the user's approximate geography, your ChatGPT visibility is inherently localized. A company with strong SEO in the US may be invisible to a ChatGPT user in Asia asking the same question. This is particularly relevant for products and services with regional availability — optimize for the geographies where your actual customers are, not just where your SEO tools default to measuring.
The Aggregator Effect
Across our test conversations, software review and comparison sites — ranking listicles, G2-style directories, industry roundup blogs — appeared disproportionately often in ChatGPT results. This makes structural sense: a page titled "Top 10 Best Cosmetic Formulation Software of 2026" contains your product name, a brief description, and a comparison context all in a single high-density snippet. Even if your own homepage ranks well, the aggregator page may be a stronger snippet match to the query "best cosmetic compliance software" because it directly answers the implied question.
Being listed in these aggregators — with accurate, keyword-rich descriptions — may be as important as your own page optimization.
Earning Labrador Coverage: The Full-Text Advantage
The Labrador pipeline, which retrieves from premium news publishers with full article text, gives ChatGPT substantially richer content about topics covered in major outlets. A Reuters article about your company means ChatGPT potentially receives multiple paragraphs describing your product, use case, and market position — compared to a 150-character snippet from your own site. Sustained investment in PR and press coverage is not just a brand exercise; it feeds a structurally richer retrieval signal directly into the model.
The Bigger Picture
The discovery that Bright Data is the named retrieval middleware for ChatGPT — with an opaque stack underneath it — has several important implications.
The search engine war is being refought at a different layer. Google and Bing are no longer the only surfaces that matter. The question of which search engine Bright Data routes to for a given query, in a given geography, for a given content type, has enormous downstream implications for visibility. That decision is currently invisible to publishers and marketers.
Geo-aware AI search is a structural shift. Traditional SEO tools measure rankings from fixed geographic vantage points. A Bright Data-powered, residential-proxy-routed AI search system personalizes results geographically by default. The tools for measuring and optimizing this don't really exist yet.
The snippet is the new rank. In traditional search, your position on the results page determines your visibility. In AI search, the model reads your snippet to decide whether to cite you. These are different optimization targets. You can rank #3 on Google and still be invisible to ChatGPT if your meta description doesn't directly answer the query. Conversely, a page that never cracks the first page of Google results might still surface in ChatGPT if its snippet is uniquely dense and answer-shaped.
The middleware black box is itself an asset. Bright Data's residential proxy infrastructure — routing queries through real user IPs across 195 countries — gives OpenAI something neither a direct Bing API call nor a homegrown crawler could provide: localized, de-personalized, human-like search results that reflect what real users actually see in any geography. That's a significant technical advantage, and it's why the relationship makes commercial sense regardless of which engine(s) sit underneath.
The playbook for ChatGPT search visibility is still being written. What we've established through direct API inspection is that Bright Data is the confirmed, named layer sitting between OpenAI's Sonic orchestrator and the results the model generates its answers from. Everything below that layer — which search engines, which blend, which cache — remains an open question. But the optimization principles that follow from this architecture are already actionable.
Try It Without Writing a Single Line of Code
The extraction script in the appendix above is the manual path. If you'd rather explore ChatGPT's search behaviour directly in your browser, Synscribe's ChatGPT Search Query Extractor gives you a point-and-click interface for exactly this data.
The extension reads the same web.run tool calls and search_result_groups metadata described throughout this article and presents them as a clean sidebar overlay — showing you:
The user prompt that triggered a search round
The reasoning title — ChatGPT's own label for what it was trying to find (
metadata.reasoning_title)Every search query in the fan-out (
system1_search_query[].q)Result count returned for that round
Fuzzified status — a badge when Sonic approximated the queries rather than executing them exactly
This is the same infrastructure this article exposes programmatically, surfaced without touching DevTools. Synscribe built it as part of their work in Generative Engine Optimization (GEO) — helping B2B brands understand how ChatGPT discovers, rewrites, and retrieves content, and what that means for appearing in AI-generated answers.
Download the free Chrome extension →
Appendix: Full Extraction Script
async function extractChatGPTSearchData(conversationId) {
const token = JSON.parse(
document.getElementById('client-bootstrap').textContent
).session.accessToken;
const conv = await fetch(
`https://chatgpt.com/backend-api/conversation/${conversationId}`,
{ headers: { Authorization: `Bearer ${token}` } }
).then(r => r.json());
const chain = [];
let nodeId = conv.current_node;
while (nodeId && conv.mapping[nodeId]) {
const node = conv.mapping[nodeId];
if (node.message) chain.unshift(node.message);
nodeId = node.parent;
}
const rounds = [];
let currentRound = null;
for (const m of chain) {
const meta = m.metadata || {};
if (m.author?.role === 'assistant' && m.content?.content_type === 'code' && m.recipient === 'web.run') {
const payload = JSON.parse(m.content.text || '{}');
currentRound = {
reasoning_title: meta.reasoning_title,
queries: (payload.system1_search_query || []).map(q => q.q),
results: [],
fuzzified: false,
sonic_thread: null
};
rounds.push(currentRound);
}
if (m.author?.role === 'tool' && m.author?.name === 'web.run' && currentRound) {
const groups = meta.search_result_groups || [];
if (groups.length > 0) {
currentRound.sonic_thread = meta.debug_sonic_thread_id;
groups.forEach(group => {
(group.entries || []).forEach(entry => {
currentRound.results.push({
url: entry.url,
title: entry.title,
snippet: entry.snippet || '',
pub_date: entry.pub_date ? new Date(entry.pub_date * 1000).toISOString() : null,
result_source: entry.result_source, // "bright" | "labrador"
content_type: entry.ref_id?.ref_type, // "search" | "news" | "academia"
domain: group.domain,
attribution: entry.attribution
});
});
});
}
const text = m.content?.parts?.[0];
if (typeof text === 'string' && text.startsWith('Displaying results for similar queries')) {
currentRound.fuzzified = true;
}
}
}
return { title: conv.title, model: conv.default_model_slug, search_rounds: rounds };
}This research was conducted by inspecting the ChatGPT backend API using an authenticated session on conversations run in June 2026. All field names, values, and JSON structures are verbatim from actual API responses. No reverse engineering, decompilation, or unauthorized access was used — only authenticated calls to endpoints accessible to any logged-in ChatGPT user. The middleware nature of Bright Data's stack means some conclusions about ultimate upstream data sources are inferred from architecture, public product documentation, and empirical result comparison rather than from direct observation.
Dominate ChatGPT and Google Search
Synscribe helps B2B companies with SEO & GEO using programmatic SEO approach. Book a call to find out how we help you win.