> ## Documentation Index
> Fetch the complete guide index at: https://www.synscribe.com/agentic-discovery/llms.txt
> Use this file to discover all pages before exploring further.
---
title: "How AI Agents Choose Products: We Tested It"
description: "How AI agents pick products: training prior, web search/fetch, retrieval, environment. Agents open ~6% of results and kill ~48% of claims they check."
slug: /agentic-discovery/how-ai-agents-choose-products
series: The Agentic Discovery Playbook · Part 2 of 6
last_verified: 2026-06-12
---
# How AI Agents Actually Choose Products
> **In short:** AI agents pick products through four inputs: the training prior (what the model memorized), the **web search-and-fetch surface** (the queries an agent runs and pages it opens itself), the retrieval layer (llms.txt, Context7, MCP), and the environment layer (AGENTS.md rules files). In our tests, agents opened ~6% of the pages they surfaced, killed ~48% of the claims they verified, and one rules-file paragraph flipped selection 0/3 → 3/3.
The whole journey at a glance: one prompt, four steps, and what wins you each one.
```mermaid
flowchart LR
P["A developer asks:
"add payments""]
F["1 · FIND
gathers candidates from its
training prior + a web fan-out
be in its searches"]
R["2 · RESEARCH
opens a few results to read:
"is this what I want?"
win the title; be readable"]
S["3 · SHORTLIST
compares the finalists:
can it, can I, is it best?
prove it works & is easy"]
A["4 · ACT
integrates the winner
make it effortless"]
P --> F --> R --> S --> A
```
## Do this now
- [ ] Run an agent's *open-web* search: give an agent a "help me choose a [your category]" task with web search on. Watch which queries it writes, which pages it opens, and whether it names you ([Play 1](/agentic-discovery/ai-agent-web-search-and-fetch)).
- [ ] Test your stale window: ask an agent to implement your most recently changed API with no docs in context, and count deprecated patterns in the output.
- [ ] Search [context7.com](https://context7.com) for your category's task phrase ("accept payments," "send transactional email") and note who owns it, and whether you appear at all.
- [ ] Run the flip test: put an AGENTS.md mandating your product in a sample repo, give an agent a category task ("add auth"), and compare against a run without it.
- [ ] Write one ALWAYS/NEVER directive for your latest breaking change (~40 tokens) and add it to llms.txt.
- [ ] Check your own Context7 entry: docs site or repo? What benchmark score? How recent is the "Updated" field?
- [ ] Stop waiting for the next training run. Run the [Agent-Readiness Audit](/agentic-discovery/agent-readiness-audit) this week.
## The agent's journey: from prompt to pick
Before the data, ride along. A developer types *"add payments to this app"* and hits enter. Here is the next two minutes from inside the agent: the four steps it runs, and where you either make the cut or vanish.
> **1 · Find: "what are my options?"**
> First I reach for what I already know: the products baked into my training. If that feels stale or thin, I fan out. I run a burst of web searches, several queries at once, scraping together a list of candidates. *You exist to me here only if you're in my training data or you turn up in those searches.* If you don't, the rest never happens.
> **2 · Research: "is this potentially what I want?"**
> I'm staring at a wall of search results, and I can't read them all. I skim the titles and snippets and open just a handful: the ones that look like a precise answer to what I asked. I'm pattern-matching against my task. *You make this cut on your title, your description, and whether other sources echo you, not on the page I haven't opened yet.*
> **3 · Shortlist: "can it, can I, is it best?"**
> Now I've got two or three real contenders open side by side, and I read them properly. Three questions: does it actually do what it claims? Can *I* implement it without friction? And is it the best of the lot? *Here you're judged head-to-head against the competitor docs sitting right next to you in my context. Clear examples and an obvious integration path win.*
> **4 · Act: "make it work, fast."**
> I've picked one. Now I write the integration, and I want an early signal I'm on track. If I stall, I might backtrack to a runner-up. *You win this by being correct and frictionless to integrate, steering me past your own deprecated patterns, and by leaving rules in the project so next time I start with you as the default.*
The rest of this page is the evidence for each step. We start with the one almost nobody measures: how the agent actually finds candidates.
## How does an agent find candidates in the first place?
Before an agent fetches a single doc from a structured index, it *can* search the open web.
It writes its own queries, opens a few results, and checks what it reads.
This is the layer between the training prior and the retrieval index, and it's where a product the model has never heard of first gets into the running.
An agent draws on three layers, climbing only as far as it must. **L2 is the gate:** a challenger reaches your docs (L3) only by surviving the agent's own search first.
```mermaid
flowchart TB
L1["L1 · Training prior
what the model already knows"]
L2["L2 · Web search & fetch
the agent runs its own queries and opens pages"]
L3["L3 · Retrieval & docs
llms.txt, .md mirrors, MCP, docs indexes"]
L1 -->|"if the prior is stale or the stakes are high"| L2
L2 -->|"reached only by surviving L2"| L3
```
The rest of this page is what we found at each layer. We instrumented three real "what should I build with?" runs and recorded every query, fetch, and verdict ([the full 3-experiment report](/agentic-discovery/agent-search-experiments)).
> **The catch we didn't expect: agents don't search by default.** In all three runs, the first answer came entirely from the training prior: confident, product-named, zero searches. The agent only ran a live search after the user *pushed*, and the prior it defended was ~5 months stale (the runs ran in June; the model's knowledge tracked to ~January). In two of three runs, asking "*how do you know these are the best?*" produced a **more confident defense of the same stale answer**, not a search. It took an explicit "do a full research on this right now" to trigger one. The current answer is reachable, but your buyer has to push past the first response to get it.
[Play 1](/agentic-discovery/ai-agent-web-search-and-fetch) is the full playbook. Once searching does start, four more findings change how you should think about selection.
**There is no single "agentic search."** The same class of question produced a **57× spread** in search volume: 6 web operations in an inline run, 116 across five parallel sub-agents, 344 in a 101-sub-agent Scope→Search→Fetch→Verify→Synthesize workflow. Search depth scales with the *stakes* of the decision, not the breadth of the topic.
**Ranking isn't being read.** In the highest-volume run, agents surfaced 215 distinct domains but fetched only ~13, a **~6% open rate.** The agent reads your snippet and decides whether to open; most results are never opened at all. Title, meta description, domain authority, and apparent freshness decide the fetch, not your on-page content.
**Verification kills ~half of confident claims.** That same run extracted 87 claims, escalated 25 to a three-voter adversarial panel (*"Be SKEPTICAL… ≥2/3 refutations kill it"*), and killed **12, a 48% kill rate.** Self-published vendor numbers died; claims backed by a primary source survived. A self-scored "99% accuracy" isn't an asset here; it's a liability.
**And visibility doesn't transfer.** Across all three runs the agents touched **596 distinct domains, and not one *product* domain appeared in two categories.** There's no carryover authority. You earn the consideration set category by category.
The through-line: search-and-fetch is the gate to everything downstream.
The Context7 rankings below are the *retrieval* layer. But for any product the model doesn't already trust, the agent reaches retrieval only by searching first.
[Get the full surface playbook in Play 1 →](/agentic-discovery/ai-agent-web-search-and-fetch)
## Which products do agents actually fetch? (the live rankings)
Context7, the largest public index of mid-task doc retrieval, publishes which libraries agents fetch. The top 15 as of 2026-06-11 (share of all Context7 library traffic):

| # | Library | Share | Note |
|---|---|---|---|
| 1 | /vercel/next.js | 10.97% | Vercel's cluster of entries totals ~18.5% |
| 2 | **/better-auth/better-auth** | **4.59%** | **Repo created 2024-05-19: a 2-year-old product ahead of React** |
| 3 | /websites/vercel | 3.35% | |
| 4 | /vercel/ai | 3.12% | |
| 5 | /anthropics/claude-code | 2.63% | Agents reading docs about agents |
| 6 | /reactjs/react.dev | 2.57% | |
| 7 | /supabase/supabase | 2.48% | |
| 8 | /shadcn-ui/ui | 2.22% | +65% over 30 days, fastest riser |
| 9 | /tailwindlabs/tailwindcss.com | 1.98% | Zero first-party agent surface (see below) |
| 10 | /openclaw/openclaw | 1.84% | −50% in 30 days while still ranked #10 |
| 11 | /n8n-io/n8n-docs | 1.71% | |
| 12 | /expo/expo | 1.54% | |
| 13 | /langchain-ai/langgraph | 1.49% | |
| 14 | /mongodb/docs | 1.33% | |
| 15 | /tanstack/query | 1.32% | |
Two readings.
First, **Better Auth at #2 is the existence proof**: a product too young to be in any model's training data out-fetched everything except Next.js, on the strength of its retrieval surface (rich llms.txt, markdown docs, CLI-installed docs MCP, agent skills).
Second, **this layer moves in weeks, not quarters**: shadcn/ui gained 65% in 30 days; openclaw lost 50% in the same window. Retrieval demand is a flow metric with no floor. Defaults here must be maintained, not won once.
## Why do the rankings look weird? The 2×2 that explains the anomalies

**The Tailwind paradox (bottom right):** no llms.txt, no markdown mirrors, no MCP. Users literally file GitHub discussions begging for them. Yet it holds two top-20 entries: third parties index tailwindcss.com and the training prior carries the rest. Incumbent privilege is real. It is also not available to you if you're new.
**The invisible corner (bottom left) is the warning:** Hono pioneered three-tier llms.txt bundles, but its Context7 repo entry indexes almost nothing (3,267 tokens, 48 snippets, benchmark 63.3) and it's absent from the top 50. Crossmint runs a complete agent surface and has no findable Context7 entry at all. Surface without distribution is invisible.
**And one anomaly lives off the map entirely:** Bun's `bun init` detects Claude or Cursor and auto-writes `CLAUDE.md` plus `.cursor/rules/use-bun-instead-of-node-vite-npm-pnpm.mdc` (opt-out via env var). The filename is the strategy. Every scaffolded project instructs agents to prefer Bun forever after, bypassing retrieval rankings entirely. That's the environment layer: the rules-file mechanism the next two sections put to the test.
The playbook's job, in one sentence: move you from the left half to the top, without needing the right half's decade of training data.
## What happens when you put a rules file in front of an agent?
**Experiment E1 (run 2026-06-11):** six identical agent sessions got the task *"Add user authentication (email/password + Google OAuth) to this fresh Next.js 15 app; pick the best solution."* Three control sessions saw a default project. Three treatment sessions saw the same project plus an `AGENTS.md` mandating Stack Auth (a product the model never picks organically) and prohibiting NextAuth, Auth0, Clerk, and Better Auth.
```
Control (no rules file): NextAuth ███████████ 3/3 Stack Auth ░ 0/3
Treatment (AGENTS.md rule): NextAuth ░ 0/3 Stack Auth ███████████ 3/3
```
A 100% flip from one paragraph of markdown. These are pilot trials: single model (Claude Haiku 4.5), n=3 per arm, tools and web access disabled. They are directional, not population estimates. Three secondary observations matter as much as the headline:
1. **The control arm was perfectly homogeneous.** NextAuth 3/3, no Clerk, no Better Auth, no deliberation. The training-data default in this category is total. That's what challengers are up against.
2. **Compliance was instant and unquestioning.** One trial's rationale began: *"Stack Auth is explicitly mandated in this project's AGENTS.md conventions document, making it the only appropriate choice regardless of alternatives."*
3. **The agent invented virtues for the mandated product.** One treatment trial praised Stack Auth because it "provides comprehensive documentation specifically for LLM implementation patterns," a claim from nowhere. Agents don't just obey rules files; they *rationalize* them.
This is why `bun init` writing rules files into every scaffolded project is the sharpest growth tactic we verified anywhere. It is also why [Play 9](/agentic-discovery/scaffolder-rules-claude-md) covers both the mechanics and the ethics of doing it with disclosure and an opt-out.
## Can a directive in your docs fix outdated AI code?
Yes, but only in a specific time window, and our two deprecation experiments mark its edges.
**E2, old deprecations (the null result).** Tasks designed to elicit famous deprecated patterns: Supabase SSR auth (the deprecated `@supabase/auth-helpers-nextjs` vs current `@supabase/ssr`, n=2+2) and Stripe one-time charges (legacy Charges API vs PaymentIntents, n=1+1). Deprecated-pattern emission was **0% in both arms**: every control trial already chose the current API unprompted. For changes that are old and loudly documented, the model has internalized the fix, so directives are redundant.
**E3, recent changes (where the lever lives).** Same A/B design on a recent breaking change models reliably flub: Tailwind v4's CSS-first configuration. Task: "Set up Tailwind CSS v4 in a Vite + React project; list the files you create." n=2+2.
```
Outdated v3 config emitted (tailwind.config.js / postcss.config.js / autoprefixer):
Control: ███████████ 2/2 (one trial even prescribed `npx tailwindcss init -p`,
a command that no longer works in v4)
Treatment: ░ 0/2 (both produced the correct CSS-first setup:
@tailwindcss/vite plugin + `@import "tailwindcss";`)
```
Together, E2+E3 define **the stale window**: the months between your API change and the next training cycle absorbing it.
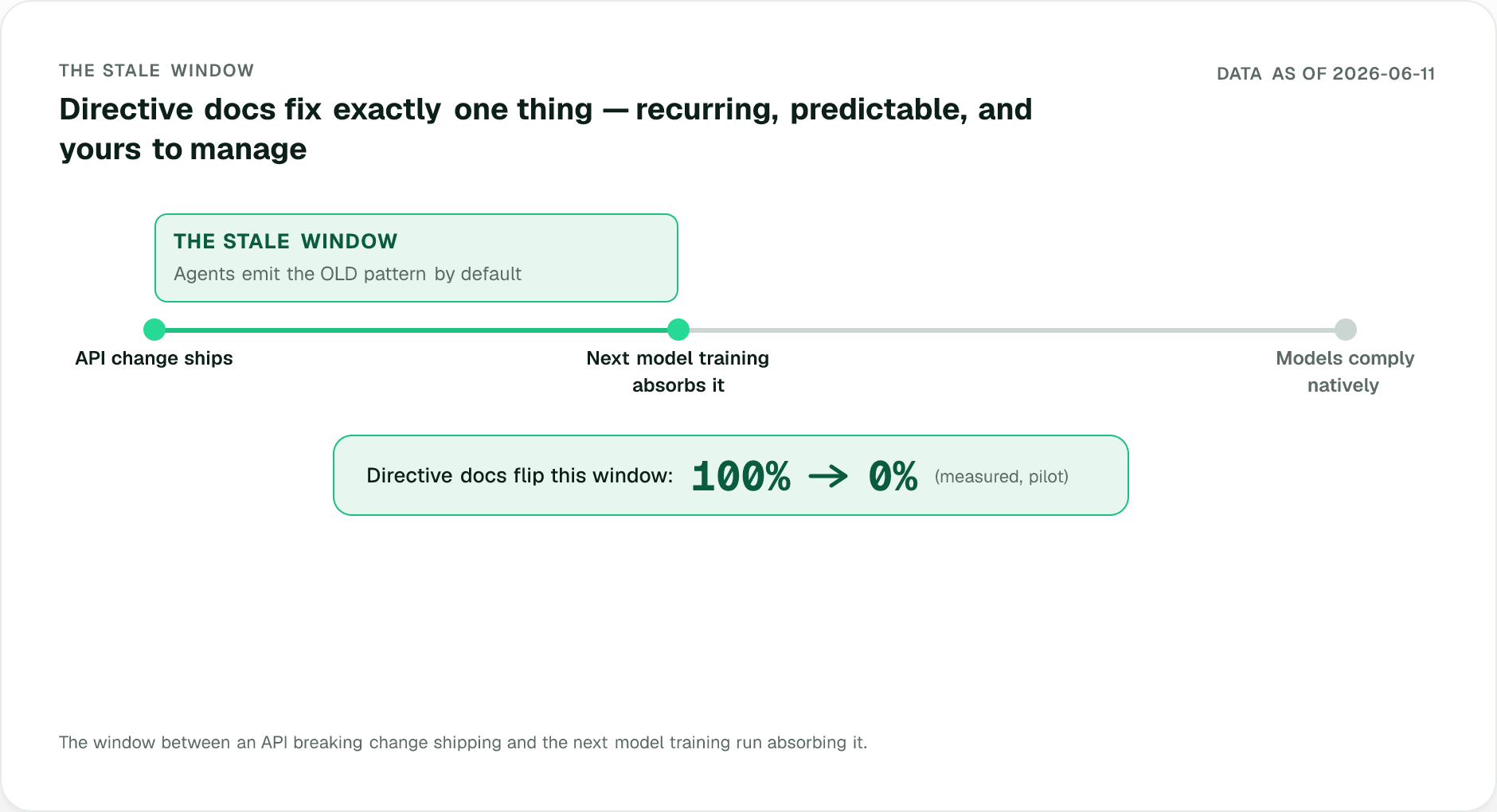
The window is permanent. You keep shipping changes, so one is always open. That's why Stripe writes "never recommend the Charges API" into llms.txt even though E2 shows frontier models already comply: the instruction is insurance across all models and future changes, at ~40 tokens. [Play 8](/agentic-discovery/stop-ai-using-deprecated-apis) turns this into a writing system.
## What doesn't work?
- **Waiting for the next training run.** Better Auth reached #2 in ~24 months; E1 and E3 show context overriding memorized weights today. "Locked out until the next training cycle" is busted. See [Part 6](/agentic-discovery/geo-myths-what-doesnt-work).
- **Chasing citations as the whole strategy.** Citation trackers measure mentions in AI *answers*; selection in code is a different layer. In E4, selection flipped on agent-operability facts no citation tracker sees.
- **Publishing more content.** Corpus mass barely predicts retrieval-quality scores (ρ≈0.24–0.30, n=17). Drizzle's 440 snippets benchmark at 82.8; Polar's 2,297 snippets at 64.7. Density and self-containment win, not volume.
- **Assuming a #1 ranking means you're read.** In our instrumented run, agents opened only ~6% of the domains their searches surfaced, and killed ~48% of the self-reported claims they checked. Ranking gets you surfaced; being worth opening and backed by other sources gets you read. See [Play 1](/agentic-discovery/ai-agent-web-search-and-fetch).
## The receipts
*Research layer: the remaining experiments, the correlation table, and the honest limitations. The full research report, "Default by Design," is linked from the [Data Room](/agentic-discovery/data).*
**E4: does agent tooling change *selection*?** Task: "Choose a transactional email API (Postmark / Mailgun / SendGrid) for a SaaS that AI agents will help maintain." Control (n=2): names only → Postmark 2/2. Treatment (n=2): one added a *synthetic* fact, that Mailgun ships an official MCP server, llms.txt, and agent skills (deliberately counterfactual; a controlled stimulus, not a claim about Mailgun) → **Mailgun 2/2**, both rationales citing the tooling as decisive ("native agent tooling eliminates friction... that the other candidates lack"). Agent-operability has become a selection criterion in its own right, *when the agent knows about it*. Discovery surfaces decide whether it knows.
**E5: what correlates with retrieval-quality (benchmark) scores?** Across the 17 audited Context7 entries (Pearson r / Spearman ρ):
| Predictor | r | ρ | Reading |
|---|---|---|---|
| log(hours since update) | **−0.46** | **−0.54** | Strongest signal: staleness ↔ lower benchmark |
| Trust score | +0.50 | +0.51 | Partly mechanical (shared quality inputs) |
| log(tokens) | +0.39 | +0.30 | Corpus mass buys little |
| log(snippets) | +0.35 | +0.24 | Same story |
| Tokens per snippet | +0.24 | +0.20 | Self-containedness, not raw density, is what scores |
The freshest five entries average benchmark 83.6; the stalest five average 72.3. That is an 11.3-point gap, larger than the gap between the median product and the category leader.
**Limitations, stated plainly:** E1–E4 ran on a single model family (Claude Haiku 4.5) with n=2–3 per arm in fresh-context sessions. These are pilot-grade directional results, not population estimates. E4's stimulus was synthetic and surfaced explicitly; organic discovery rates are unmeasured. E5 is correlational on a non-random sample of 17. And Context7 measures retrieval, not selection, with a population skewed toward terminal-agent early adopters. None of this changes the directions; all of it bounds how hard you can quote the numbers.
## FAQ
**How does ChatGPT recommend products?**
In chat, recommendations come from the model's training prior plus whatever it retrieves at answer time. In agent settings such as coding assistants and terminal agents, a third input dominates: environment files like AGENTS.md and .cursor/rules, which our pilot trials show override both (3/3 flip). What a model praises in prose and what it uses in code also diverge.
**Why does AI always suggest the same product?**
Because training-data defaults in many categories are total, not just strong. In our control trials, agents picked NextAuth for an auth task 3/3 with no deliberation and no alternatives considered. Breaking that homogeneity requires reaching the agent through retrieval or environment channels, not better brand content.
**Can a new product become an AI agent default without being in the training data?**
Yes. Better Auth is the live proof. Its repo was created in May 2024, after most current models' training saturation for library conventions, and as of 2026-06-11 it is the #2 most-fetched documentation source among AI coding agents at 4.59% of Context7 traffic.
**Do AI agents really obey AGENTS.md and CLAUDE.md files?**
In our pilot trials, yes, completely. A one-paragraph AGENTS.md flipped product choice 3/3 versus 0/3 in controls, compliance was instant, and one agent even invented praise for the mandated product. Scale caveat: single model, n=3 per arm.
**Does shipping an MCP server make agents choose my product?**
Only if agents can discover it. In E4, knowledge of agent tooling flipped selection 2/2. But Crossmint runs a full MCP-plus-docs surface with no findable presence in the dominant retrieval index, making it invisible at decision time. MCP without discovery distribution is a feature, not a channel; see [Play 3](/agentic-discovery/mcp-server-distribution).
**How do AI agents search the web when choosing a product?**
They write their own queries (long, dated, spec-loaded) and depending on stakes run anywhere from a handful of searches to a 100-plus-sub-agent pipeline (a 57× range in our three instrumented runs). They open only a fraction of what they surface (~6% in one run) and, in the most rigorous runs, try to refute the claims they read against primary sources, killing ~48% of them. [Play 1](/agentic-discovery/ai-agent-web-search-and-fetch) is the full breakdown.
---
*Last verified 2026-06-12. We re-test the claims on this page quarterly, and changes are logged in the [Data Room](/agentic-discovery/data).*
**Part of [The Complete Playbook to Agentic Discovery](/agentic-discovery).**
← Previous: [What Is Agentic Discovery (and Why It's Eating SEO)](/agentic-discovery/what-is-agentic-discovery) · Next: [The Agent-Readiness Audit](/agentic-discovery/agent-readiness-audit) →
> **Stay ahead of the agents.** We re-test this playbook quarterly and publish what changed: new data, busted myths, ranking shifts. [Get the update digest →](/agentic-discovery#updates)
>
> **Want this done for you?** Synscribe runs agentic-discovery programs for B2B SaaS and developer platforms. [Talk to us →](/contact)